Re-Scoring an ML Detection Engine on Past Attacks
Developing a machine learning product for cybersecurity comes with unique challenges. For a bit of background, Abnormal Security’s products prevent email attacks—think credential phishing, business email compromise, and malware—and also identify email accounts that have been taken over. These attacks are clever social engineering attempts launched to steal money (sometimes in the millions) or gain access to an organization for financial theft or espionage.
Detecting attacks is hard! We’re dealing with rare events—as low as 1 in 10 million messages or sign-ins. The data is high dimensional—all the free-form content in an email and linked or attached in an email. We require bleedingly high precision and recall. And, crucially, it is adversarial—attackers are constantly trying to outsmart us.
These factors have consequences for our ML system:
- The adversarial nature of the problem means the attack distribution is constantly shifting, so we must keep improving models. Attackers are often even using ML systems of their own to adapt their attacks!
- Due to the rarity of attacks, we must retain every precious sample. We cannot afford to throw out older attacks simply because they do not have the latest features. We must instead re-compute these features.
- Due to high dimensionality and volume, it is a big-data problem and requires efficient distributed data processing.
To build a platform and team that can operate and improve our detection engine at high velocity, we must enable ML engineers to experiment with changes across the entire stack. This includes changes to underlying detection code, new datasets, new features, and the development of new models.
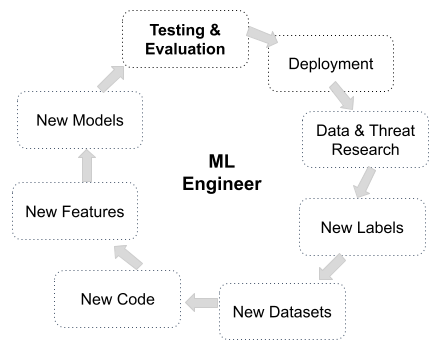
This loop is reminiscent of a software engineering CI/CD loop, but there are more moving pieces. When developing detectors, there may be new code involved, new datasets that must be served online and offline, and new models. We must test this entire stack thoroughly, and the easier it is to test, the easier it will be to safely iterate.
Why is testing the detection stack so important? Think about what could go wrong... if, for example, we make an unintentional code change that modifies a feature used by a model but we do not retrain the model, the effect could shift distributions, incorrectly classify, and miss a damaging attack. Since our system acts at incredibly high precision and recall, small changes can cascade to have large consequences.
Re-generating an Updated Labeled Dataset
Our rescoring system has three important components
- Golden Labels: The set of all labeled messages with features updated with the entire detection stem including recent code, joined data, and prediction models. We affectionately call this dataset “Golden Labels.” It’s the gold standard label set, and it is also precious because it contains all attack examples from the past. This dataset feeds into the following two processes.
- Rescoring: Process to evaluate the entire detection system to produce performance analytics like precision and recall. We call this “rescored recall.” For example, we measure what percentage of historical attacks we would catch today with the current detection system. Note: This is different than precision and recall evaluation on individual models on an evaluation set because we are testing an entire stack that includes multiple models, decision logic, feature extraction code, and datasets.
- Model Training: Like rescoring, re-training models requires up-to-date Golden Labels data. We must have correct and unbiased features to train our models so that the data observed when training matches up to the data at inference time. The features that feed into model training are organized as a DAG of dependencies where some features rely on other features or models.

Requirements for Data Golden Labels Re-Generation
For data that feeds into rescoring and model training to be effective, we have several requirements:
- (rescore requirement) - Should be able to update historical samples with the latest attribute extraction (1) code, (2) joined datasets, and (3) model predictions and evaluate proper and trustable analytics.
- (unbiased feature requirement) - Re-computed features on old samples accurately reflect how those features would appear if that sample were encountered today.
- (time-travel requirement) - To produce unbiased aggregate features, the system must perform time-travel: evaluate samples as they would have looked at the time of the attack. Time travel ensures unbiased data and also helps us avoid future leakage: avoiding bringing any data from the future (to a past sample) that leaks labels into training features.
- (developer effectiveness) - ML engineers must be able to easily develop, integrate, and deploy their changes to any area of the detection stack. Must be efficient enough to run frequently to retrain and evaluate changes and ad-hoc evaluations to answer “what-if” type questions.
Ad-Hoc Rescoring Experiments
In addition to the automatic daily re-generation of “Golden Labels” tagged to a particular code branch, we additionally have an Ad-Hoc rescoring pipeline allowing engineers to ask “what if” questions—that is, what happens to overall detection performance if we change one or more pieces of the system.
For example, we may not need to re-run the entire feature extraction stage if we are testing only a new model and the downstream impact of that model. To do so, we rely on the most recent updated Golden Labels from the night before and run additional steps:
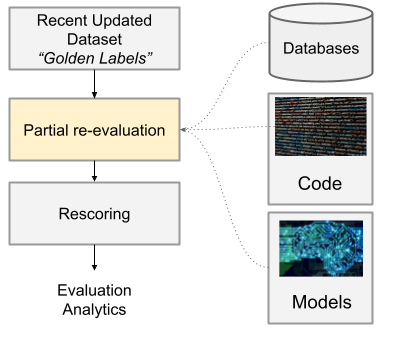
Example of an Ad-Hoc Rescoring Experiment
We can either set up two configurations, “Baseline” and “Experiment,” or run this on two different code branches. It’s up to the ML engineer to decide how to run their experiment correctly. Eventually, we would like our CI/CD system to run rescoring on stages affected by particular code changes and automatically provide metrics, but for now, it is manual.
This example configuration tests what happens when we swap out a single model.
# Baseline configuration runs model scoring and decisioning. baseline_config = RescoreConfig( [ MODEL_SCORING, # Evaluates ML models DETECTION_DECISIONS, # Evaluates our detection decisions using the model scores. ] )# Experimental setup to swap a single model. experiment_config = RescoreConfig( [ MODEL_SCORING, DETECTION_DECISIONS, ], FinalDetectorRescoreConfig( replace_models=[ReplacementModelConfig( model_path="/path/to/experimental/model", model_id=ATTACK_MODEL )] ) ) # Runs the rescoring and delivers analytics to the user. run_rescoring( rescore_config=rescore_config, baseline_config=baseline_config )
We can use a similar system to generate model training data with experimental features.
Running Rescoring Efficiently
Both automatic and ad-hoc rescoring require a lot of heavy lifting behind the scenes. We run everything on Spark, and there are a lot of tricky data engineering problems to solve to satisfy the requirements listed above, especially the time travel problem. Read Part 2 of this Re-Scoring an ML Detection Engine of Past Attacks series for information on how we built this system.
And if you're interested in solving tough applied ML engineering problems in the cybersecurity space, we’re hiring!
Thanks to Justin Young, Carlos Gasperi, Kevin Lau, Dmitry Chechick, Micah Zirn, and everyone else on the detection team at Abnormal who contributed to this pipeline.

Get AI Protection for Your Human Interactions




Related Posts





