Scaling in a High-Growth Environment
At Abnormal, the problems we are trying to solve are not that much different from those being tackled by other organizations, including large enterprises. What is unique to startups are the additional constraints placed on the solution space, such as the amount of time, money, resources, and engineers that can be thrown at a problem. In this series, we will explore some of the challenges we face and the unique ways we have overcome these challenges.
Approaching the Limit for Number of Supported Mailboxes
We recently were faced with the challenge of scaling our online KV (key-value, a.k.a., NoSQL) datasets, which had become one of the biggest limiting factors for us to take additional traffic from new customers. This was primarily driven by two datasets, Behavior DB and Mailbox DB. Note that there is a third dataset, Person DB, but that is a story for another day.
The former, as its name suggests, is a dataset containing statistics about the behavior associated with all messages sent to or from an organization, as well as the individuals involved. The second is a dataset containing metadata about each mailbox, or email account. Both of these datasets grow linearly with the number of mailboxes being protected. Additionally, Behavior DB grows with the average number of data points generated per message.
We knew this was going to be an issue that we had to face at some point, but made the conscious decision to delay investing in a solution until the issue became more urgent. The issue became urgent when we only had enough runway to increase the number of mailboxes being protected by approximately 25%, with a projected mailbox growth of 100% in the two months that followed.
How This Happened
Before we start, it would be helpful to have some shared context. If we zoom all of the way out, at the heart of the real-time component of our email protection product is the Real-Time Scorer, more affectionately known as the RT Scorer:
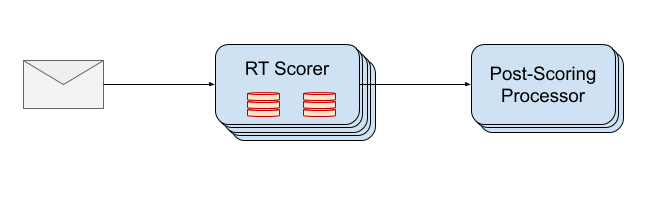
When an email message is delivered, it is first sent to the RT Scorer to generate a judgment of safe, suspicious, malicious, etc. and is then sent along to the Post-Scoring Processor to take action related to the judgment, such as quarantining the message if it is malicious, injecting a banner in the body of the message if it’s suspicious, or surfacing the threat in the customer portal if it is an unsafe message. The RT Scorer extracts metadata about the message, including sender, recipient, email headers, etc. and collects data related to the entities of the message such as sender, recipient, and attachments, and then passes that data on to the various detectors to provide a judgment. The RT Scorer is a stateless service running in a docker container. It scales horizontally with message volume by adding more instances. In theory, it should be infinitely scalable.
In the early days, Behavior DB and Mailbox DB were both small. We had a dozen or so instances processing double-digit queries per second (QPS) protecting approximately ten thousand mailboxes spread across a handful of customers. Behavior DB contained about 5 million keys, which fit nicely into a 100 MB database file. Mailbox DB was smaller and could easily fit into 20 MB. These datasets were (and still are) generated in batch using Spark and are updated daily.
Back then, we were faced with the difficult decision about how to make these datasets available to our detection system. Like many decisions, this one was about tradeoffs. In the startup life, time is precious and these decisions must be made quickly; there generally isn’t enough time to complete an in-depth evaluation of each viable option. Using familiar technologies (even though it may not be a perfect fit) and using them in simple ways brings velocity and a high chance of success. For the first version, we ultimately chose to keep the system simple and distribute the datasets to all RT Scorer servers so that they could access the data locally and not have to worry about the complexity of adding a remote procedure call into what was a self-contained, monolithic service. This simplicity and speed came at the cost of technical debt of a system that would not scale well. Behavior DB was deployed as a RocksDB database and was accessed via a library, directly off of disk. Mailbox DB was deployed as a compressed CSV file and was loaded into memory.
As our detection system became more sophisticated, the number of keys per message being materialized in the Behavior DB grew and so did its size. As the number of mailboxes we were protecting grew, so did the size of both datasets. By May 2020, both Behavior DB and Mailbox DB had grown by two orders of magnitude. The process of loading, unpacking, and opening these datasets was now taking more than 10 minutes and used a considerable portion of memory. Since the RT Scorer could not function without these datasets, this severely impacted our ability to launch new instances, affecting auto-scaling operations (it was sluggish), deploys (what used to take 10 minutes was taking over an hour), and S3 transfer costs (which were inflated). Mailbox DB would soon exhaust the available memory on the RT Scorer and to increase this, because of some fundamental technical details of how the RT Scorer is built, would mean running the servers with twice the memory and CPU at twice the cost, without the ability to utilize the additional compute power.
Assessing our Options
We were faced with a problem. We were projecting the number of mailboxes to grow by a factor of five by the end of the year, and then by another factor of ten by the end of the following year. More urgently, the mailbox count was set to double in the next two months.
We faced the following challenges:
- A compressed time schedule. We had 3–4 weeks to roll out a solution.
- Limited resources available. We had to continue to support other development, leaving only 1–2 engineers to work on a solution.
Our solution must have met the following requirements:
- Support growth rate of the next year at a factor of 50.
- Support very large customers with hundreds of thousands of mailboxes.
- Eliminate the long startup problem.
- No (or negligible) impact on processing latency.
Given these requirements and restrictions, we looked at our options. What follows are the most promising ones:
Option 1: Partition RT Scorer by customer and scale horizontally by adding more clusters as more customers are added.
Pros:
- Low engineering effort, since customers are already partitioned to some extent, so all the pieces are already in place.
- “Infinitely” scalable by adding partitions/clusters as customers are added.
- Low risk because the RT Score is used as-is but deployed differently.
Cons:
- Additional operational overhead of managing separate clusters. Partitioning is sticky since a customer can’t easily be move between clusters, there is a need to assign/route each customer’s traffic to the right cluster, complicating the routing layer, and this can lead to imbalanced partitioning if no corrective action is taken.
- This doesn’t address slow launch problem.
- It doesn’t support very large customers that can’t fit on a single partition.
Option 2: Scale the RT Scorer vertically by adding bigger disks, adding more memory, and caching datasets locally.
Pros:
- Solves the slow launch problem.
- No additional operational burden.
- Low risk.
Cons:
- Won’t support growth by a factor of 50, as it's limited to a factor of about 20.
- Data distribution continues to be a problem as we struggle to efficiently distribute hundreds of GB.
Option 3: Publish data to a KV Store such as Voldemort, Redis, Cassandra, or others.
Pros:
- Checks all the boxes.
Cons:
- High risk with significant changes required to support a new data model.
- Remote access is more complicated than local access.
- Likely requires changing how data is generated.
- Not many off-the-shelf options for serving batch-generated KV data. Voldemort seems abandoned and has known latency issues when updating datasets and Terrapin was abandoned.
Given all the pros and cons, Option 3 (Publishing Data to a KV Store) seemed the most promising. However, it would introduce some risk.
- May require changes to how data is distributed since currently, data is pulled from S3.
- Would require substantial effort to validate data parity between new and old datasets.
- May require managing a new, complex server for which the team has limited experience.
Is there a way to get the best of both worlds? Could we take our existing RocksDB datasets and serve them from a centralized service? If so, this would eliminate much of the risk.
The Solution
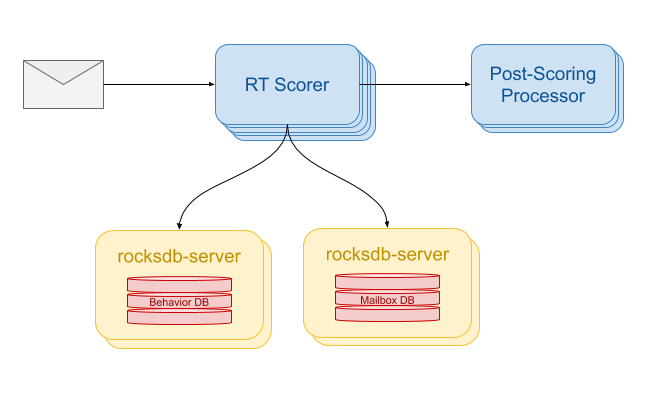
The approach we took was to use the current RocksDB dataset and serve it using rocksdb-server. rocksdb-server a simple service that exposes a Redis-compatible API on top of the RocksDB API. It serves a single database at a time and implements a tiny subset of the supported commands. This is a great solution for our use case because:
- We have experience with Redis and already have a Redis client and tools for accessing Redis servers.
- It uses the exact same dataset format, eliminating the risk associated with a new data format and any discrepancies that could creep in.
- rocksdb-server is very simple, further reducing risk by making it easier to debug, fix, and extend.
- Limited mostly by the size of disk that is available.
- Low latency—under load we achieved sub 1ms p99 latency.
With these new servers, the RT scorer diagram now looks like the following:
The Plan
Introducing changes to any system comes with risk. In general, the more significant the change, the higher the risk. There are several patterns that can be followed to help de-risk any project. In this case, we chose the following strategies:
- De-risk the high-risk items as soon as possible.
- Break down execution in Crawl/Walk/Run phases.
- Launch in “dark mode” to validate the solution.
De-Risking the High-Risk Items
High-risk items can upturn an otherwise sound solution and waiting too long to figure this out can jeopardize its delivery. For this solution, there were a few things that we didn’t know or were worried about. In this particular case, most of our worries were around the rocksdb-server, since we had no experience with it. Specifically:
- Will it be performant enough?
- How many replicas will we need?
- What latency will we likely see?
- Does it support the functionality we need and/or can it be easily extended if it doesn’t?
The approach we took to de-risk this solution was to first create a docker image that would download an arbitrary dataset from S3 and launch rocksdb-server pointing to that dataset. Once this was done, it became possible to test all of the performance-related risks. More on this later.
Crawl/Walk/Run
Crawl/Walk/Run is an approach to delivering value that encourages early successes. It is an invaluable technique that demonstrated its value in this project. Thinking this way helps you focus on small improvements that deliver value without having to build the perfect solution right away. Build something small, learn, and improve over time. To solve our problem, all we have to do is crawl—we don’t need to run.
For the crawl, we were able to sacrifice some of the functionality that would be needed in the future but not needed now. For example:
- Horizontally Scalable as the Datasets Increase in Size: Although we can horizontally scale to higher QPS by deploying more replicas of the data, we must vertically scale to machines with larger disks and RAM as the datasets increase in size. The Redis protocol supports sharded datasets, which rocksdb-server could be extended to support.
- Efficient Distribution of Datasets: We ended up productionalizing the proof-of-concept docker container that downloaded the datasets at launch because it was good enough for now. This can be addressed later when the datasets are too big and this is no longer a practical solution.
- Live Dataset Updates: Updating the version of data being served requires restarting the service by triggering a download of the latest version. Although this is a bit awkward, a load balancer can gracefully handle instances disappearing and it greatly simplifies the solution.
- Server-Side Metrics: On the server side, we are limited to system-level metrics—CPU and memory utilization—without any application metrics, including latency, QPS, etc. It would be great to have these, but would require more changes to rocksdb-server. The client side metrics, although far from perfect, can fill in a lot of the gaps here.
Sure, without this functionality our solution is very rough around the edges, but it’s solving a big problem.
Dark Launch
Even with the most thorough testing, it’s hard to say with absolute certainty that an implementation will not break things. This is especially true when replacing one already-working-thing that others are depending on with something else. A common technique to mitigate this risk is the dark launch. In a dark launch, the new solution is exercised to its fullest but results are not used. Typically, it’s controlled by a knob that can send anywhere from 0% to 100% of traffic through the new solution.
In the case of Behavior DB and Mailbox DB, our dark launch consisted of the following functionality.
- Fetch data from the primary storage. Initially, this was local storage.
- Check to see if this request is selected for dark read. If not, return the results from the primary storage.
- Asynchronously fetch data from the secondary storage. Initially, this was remote storage.
- Return the results from the primary storage.
- When the results from the secondary storage becomes available, compare the results to that obtained from the primary storage and record the results.
This was controlled by dynamic configuration that indicated the percentage of requests that should be asynchronously fetched from secondary storage. A second flag controlled which percentage of requests used the remote storage as primary instead of the local storage. With these two flags, we were able to slowly increase the traffic sent to the new rocksdb-server instances and observe how they performed, as well as transition the remote storage from dark mode to live mode without having to redeploy any code.
By modifying these flags and looking at the comparison and latency metrics of the remote storage, we could be certain that the new remote storage provided byte-for-byte identical responses to the existing local storage and that the latency was within specification—all without negative impact to production traffic.
The Rollout
We had a smooth rollout. All of the instrumentation we added was able to uncover issues that we were able to fix. Some of these fixes came in the form of improvements to rocksdb-server, which can be found on the scale-up branch of this fork.
We experienced two main issues during dark launch: excessive latency and discrepancies between old and new storage.
The source of the discrepancies was an interesting problem to track down and worthy of being covered with greater depth in a follow-up post. In short, the problems that we encountered had two main causes:
- rocksdb-server and RT Scorer instances would update at different times, resulting in discrepancies in the comparisons until they became synchronized again, and
- A latent bug in how we had split customer traffic between two clusters was not consistent with how the data was split so some data was missing for some customers (with a 0.5% miss rate)
Tracking down latency issues was a similarly interesting problem to solve, and also worthy of being covered in a follow-up post. Briefly, we tracked down the following sources of latency:
- Opening the database in read/write mode: In our use case, we are serving read-only data. The RocksDB library can open a database in read-only mode, which will disable a significant amount of locking, allowing for multiple threads to read at the same time without blocking. Additionally, we used this to reject any mutating request before even hitting the database.
- Accessing RocksDB from libuv event loop: libuv is an asynchronous I/O library that works on the premise of a single event loop thread. If a call into the RockDB library from the event loop thread blocks, it blocks all connections and serializes access to the database. Ideally, RocksDB library would use libuv to asynchronously read from disk. Since it does not, calling into the RocksDB library was moved to a thread pool.
- Writing diagnostic log events in libuv event loop: As we made changes, we added a lot of diagnostics to rocksdb-server. Similarly to accessing RockDB, this can stall the libuv event loop. A buffer was added and flushing was moved to use async I/O.
- Noisy Neighbors: We initially deployed these servers in shared general-purpose infrastructure. Although this infrastructure has good memory and CPU isolation, it does not have any disk isolation. Further, disk space was provided by network attached storage, which can have slower I/O times. In this environment, our services were often deployed on the same hardware as other containers with high disk I/O, and our I/O suffered. To address this, we moved our service to dedicated resources with directly connected, fast SSD drives, which made a huge difference.
Overall, I think this was a very interesting and successful project. We were able to swap out the database from our application without any impact in production, reduced startup time from 10+ minutes to 30 seconds, and gave us enough runway to work on improving the “Crawl” and to focus on solving other problems.
Future Work
Behavior DB and Mailbox DB have each grown 3x in size since we started working on our read-only KV Store server six months ago. Although they are still holding up, there are some short- and long-term improvements we would like to make.
- Improved Visibility: We use prometheus to monitor all of our services. We would like to add support for exporting metrics in this format, giving us server-side metrics.
- Live Updates: In order to reduce downtime and more efficiently distribute the datasets to the nodes, we’d like to introduce a sidecar that manages the data on disk and notifies the main service when more data is available.
- Data Sharding: We would leverage Redis’ cluster extensions to support splitting data across multiple shards to serve very large datasets.
- Other Storage Formats: rocksDB data format is great for read/write datasets but is suboptimal for read-only datasets. This will soon become a bottleneck for generating our datasets in batch. Support for a file format that is MapReduce friendly, such as Voldemort’s read-only format, would improve this greatly.
Beyond improvements to how we serve batch data, there is still more to do to help scale the business! We need to figure out how to efficiently scale the RT Scorer 10x and beyond. As a force multiplier for the organization, the infrastructure/platform team needs to figure out what common design patterns to provide to engineers, such as data processing and storage solutions, and how to better support a growing engineering team. We must make it easier for engineers to build, test, deploy, and monitor low-latency, high-throughput services so they can spend more time solving customer problems and less time deploying and maintaining services. If these problems interest you, yes, we’re hiring!
Get AI Protection for Your Human Interactions




Related Posts





