Outgrowing Your In-Memory DB and Scaling with Microservices
In a recent post, our Head of Platform & Infrastructure Michael Kralka discussed how Abnormal’s rapid growth has forced us to make our core services horizontally scalable. In-memory datasets that start off small become huge memory consumers before you know it—forcing services to scale up rather than out. In this post, we cover how we moved our final in-memory dataset to its own remote micro-service, and what benefits we reaped in the process.
About the PersonDB
First, a few details about this dataset—PersonDB. PersonDB contains data about our customers’ employees—the users that Abnormal protects. With each email that Abnormal processes, the sender and recipient information is matched against PersonDB, and whether or not there’s a match affects how we score that message. The score is a deciding factor in whether we consider the message a threat to the recipient.
In Abnormal’s early days, PersonDB was generated offline as a modestly-sized CSV, and loaded in-memory into any online systems that need to query it. Some shared libraries would load the CSV into various internal data structures, and make it available for lookups (including fuzzy lookups) to score messages and train future ML models. Since the dataset was manageable in size, memory usage was hardly a problem. As we grew to handle thousands of more mailboxes, our memory consumption grew as well.
Issues with our PersonDB Setup
Fast-forward to late 2020, and the uncompressed CSV data grew to 4G, which is still not terrible… but with all the layered internal Python data structures that the data was loaded into, it exploded into a solid 20G. Given our scale projections for the next 6–12 months, this was about to quickly grow into triple-digit gigabyte memory consumption per instance of our online services. Not only would our online services require expensive compute instances with a large amount of memory, but our costs would also skyrocket, and we’d always risk hitting our memory limits when onboarding new customers.
There were other downsides associated with our services having to grow vertically. For example, we decided to shard one of our core real-time services by customer. Cluster A would process requests for some customers, cluster B for others, etc. By sharding, we aimed to load only the subset of customer data that was relevant to that cluster, thereby working around our vertical scale. However, this introduced a lot of custom logic and pipelines just to manage different clusters—at an estimated cost of dozens of engineering hours a month. It also has the downside of not being able to easily model the network of employees between customers if we ever wanted to do that in the future, because the data had been split up.
Finding a Solution
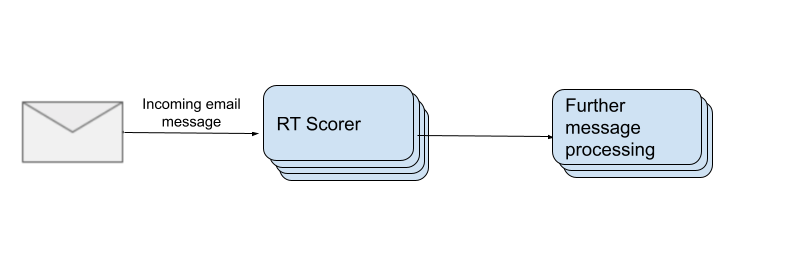
Background: Abnormal Realtime (RT) Scorer
First, a quick recap on our real-time email scoring system (RT Scorer):
… If we zoom all of the way out, at the heart of the real-time component of our email protection product is the Real-Time Scorer, more affectionately known as the RT Scorer.
When an email message is delivered, it is first sent to the RT Scorer to generate a judgment of safe, suspicious, malicious, etc. and is then sent along to the Post-Scoring Processor to take action related to the judgment, such as quarantining the message if it is malicious, injecting a banner in the body of the message if it’s suspicious, or surfacing the threat in the customer portal if it is an unsafe message. The RT Scorer extracts metadata about the message, including sender, recipient, email headers, etc. and collects data related to the entities of the message such as sender, recipient, and attachments, and then passes that data on to the various detectors to provide a judgment. The RT Scorer is a stateless service running in a docker container. It scales horizontally with message volume by adding more instances. In theory, it should be infinitely scalable.
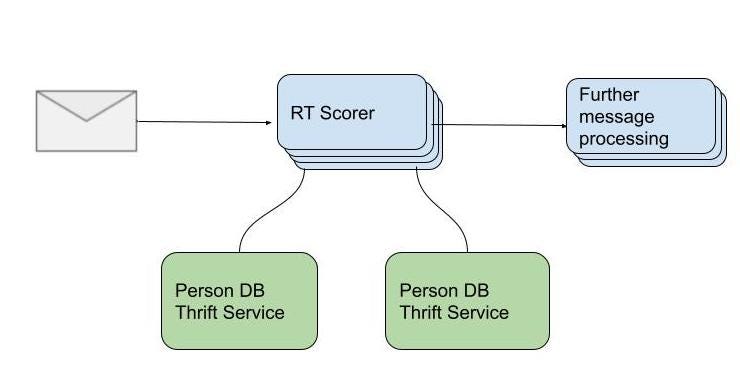
PersonDB Microservice
You might’ve already guessed that we decided to make the PersonDB data available remotely instead of locally, so we could fetch the data over a network connection to a separate pool of database servers. The requirement for the database is roughly described as “a Key-Value Store that also supports fuzzy lookups”. Note that ‘fuzzy lookups’ are lookups that may not be exact matches, but a close guess. The natural instinct might be to find a reliable off-the-shelf database that supports this.
But it turns out that it’s non-trivial to support all of our fuzzy lookups and custom business logic using generic K-V stores. Databases like ElasticSearch are certainly very powerful and support fuzzy lookups, but it’s expensive, and at Abnormal’s scale, such costs can really add up. Re-implementing our PersonDB business logic around ElasticSearch would be non-trivial as well, adding to the migration complexity and timeline.
To limit the number of unknowns and optimize for the biggest return on engineering time, we decided to serve the very same PersonDB code over HTTP via a Thrift-based Python microservice, served via a Gunicorn application server. What would’ve been a complicated and dragged-out migration became more of a refactor. That doesn’t mean there weren’t plenty of challenges anyway!
Rolling Out the New Microservice
This was an inherently risky procedure. Sure, we were technically invoking the same code as earlier, but over HTTP. However, as a cybersecurity company, processing errors are especially costly to us, and we were making changes to the backbone of our product here. Even one error per million requests could give attackers a chance to compromise our customers’ emails. We needed 100% accuracy, reliability, and correctness in our remote API calls. There was no room for errors.
Accuracy & Correctness: We covered our bases here with a ‘dark launch’. The general idea is the following—present data is loaded from code path A (local code), and future data (what we’ll migrate to) is loaded from code path B (remote API call). For every call, let’s compare both results, and track any discrepancies with metrics.
Reliability: With microservices, remote calls can sometimes fail. We needed a 100% success rate; otherwise, we might fail to protect our customers. We had our metrics and alerts wired up to make sure our calls had a 100% success rate. Only once we had addressed any RPC bugs, and added sufficient error handling to get us to 100% success at all times, did we continue with ‘live reads’ and actually use the data from the new code path.
Results of Our New Microservice
Our results were great. The most notable ones are included here.
We reduced memory consumption by more than 30% to ~20G out of 60G. The main goal was to prevent vertical growth of our services. Not only did we reduce memory consumption, but memory consumption on our real-time services was also no longer a function of the size of our PersonDB. Instead, we moved this vertical growth of memory consumption to only the PersonDB service, which we can scale independently in the future. Earlier, more people in PersonDB meant more memory usage per instance in every service, but this is only a tiny factor now. Our services became horizontally scalable.
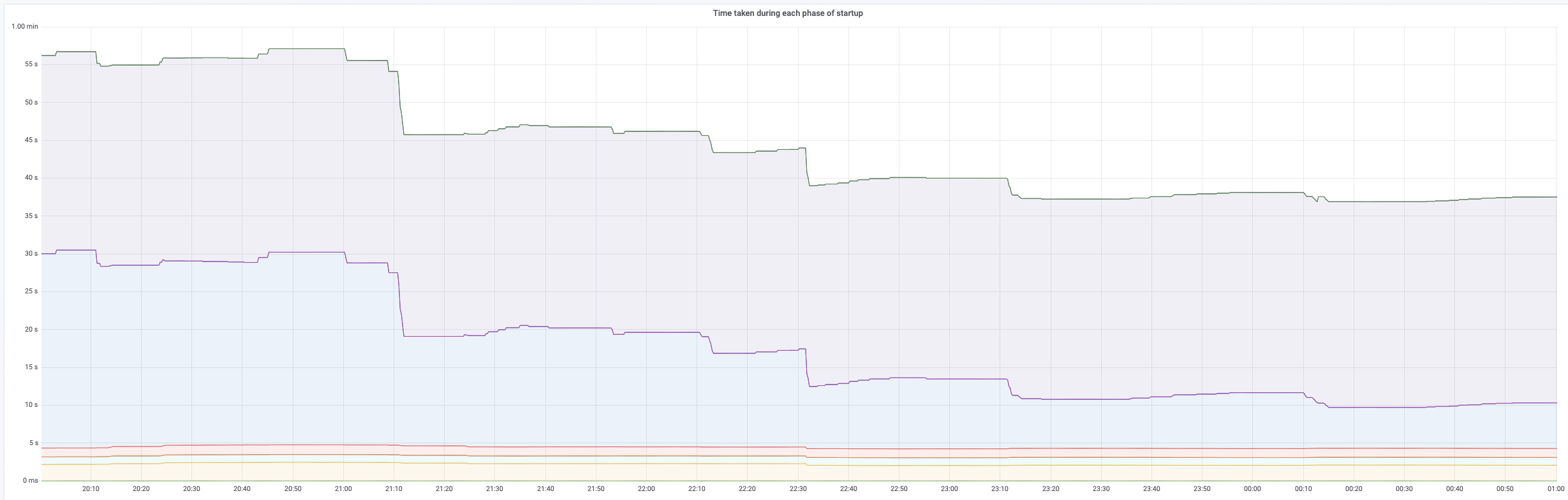
We reduced startup time by 50% from 1min to < 30 seconds. Before the migration to the remote PersonDB Service, each instance of the cluster would download the data locally when it started up, and this took time. Since the data was now available remotely, we shaved off all the downloading time. With faster startup times, deploys became much faster, as did auto-scaling.
We saved dozens of hours of engineering time per month. Without local data, we no longer needed to shard data by customers. We combined our clusters into a single cluster, and removed all the processes, overhead, and custom code that handled our shards.
Bumps in the Road to Success
It would’ve been nice if migrating to our new remote data source was as simple as swapping out the implementation layer. But we faced several challenges.
Batching
Before the migration:
- PersonDB data fetches/queries were sprinkled across the codebase. Sometimes the same query was repeated in different places.
- If a message had N recipients (where N can sometimes be in the 1000s), we were making 1 query per recipient—N requests total for the message.
While this wasn’t the cleanest code setup, it had no real performance penalty. However, with the upcoming migration, we couldn’t afford to make so many remote calls per message that we processed.
- We needed to make a single batch call per message.
- We needed our code to enforce that features written in the future would respect the batch-fetch pattern.
With these requirements in mind, we undertook a large refactor. We made the data-flow more first-class, carefully architecting the flow of database lookups into the downstream code that needed it. First, we defined all the required queries upfront, and in one place to enable batching. We stored the batched lookup results in a transient (per-message) in-memory data structure, and our downstream ML feature extraction code would only interact with our designated data structure.
We always knew that batching would bring major benefits but hadn’t quantified them precisely. After merging and deploying our admittedly nerve-racking refactor, we saw a 5x reduction in requests made to our new remote PersonDB service.
The importance of batching calls to the service can’t be understated:
- We would now always make a single PersonDB request per message, thereby protecting our real-time scoring from latency induced by too many remote requests.
- With batching, our Real-Time Scoring service now needs to make 5x fewer calls to the new PersonDB service, which has cost and stability savings.
- The query load to the PersonDB service became more predictable. As we mentioned earlier, a single message with 1000s of recipients would’ve previously resulted in 1000s of corresponding remote calls. Now it’d be just one every time.
Bugs
I’ll talk about two of the more interesting bugs we had to fix.
Discrepancies between old and new data: As I mentioned earlier, we used a ‘dark launch’ or ‘dark reads’ to compare old and new data, to ensure 100% parity. However, we saw more like 99.9% parity. It was a real head scratcher because the underlying code should’ve been the same. It took many different investigation strategies to account for all the differences:
- Top-down from the code: We looked at our code and sniffed around for any non-deterministic behavior, since it seemed like a reasonable cause. After a while, we noticed that some queries had multiple results, and were de-duplicated using a Python Set. Sets don’t promise any ordering, but there were places where we’d resolve the multiple results by choosing the first element. Since the first element of a Set could be any element, there were situations where the same query would return different results on subsequent calls. We determined it was okay to actually return multiple results and not arbitrarily choose the first. Easy fix, great! But now we were still only seeing 99.99% parity—error down 10x from 99.9% though.
- Bottom-up from the data: Where was that 0.01%… It seemed like we’d exhausted all possible offending code paths, or we were going in circles. The underlying data should’ve been the same, but we double-clicked to confirm. Remember how our real-time services had been partitioned by customer to accommodate for growing memory? Let’s call the totality of PersonDB the ‘ALL’ partition, and the partitioned components ‘PartA’ and ‘PartB’. It should’ve been the case that ALL == PartA + PartB. But our pipelines actually sometimes allowed ‘PartA’ and ‘PartB’ to be updated before ‘ALL’. We only confirmed that there could be the tiniest difference by concatenating the latest ‘PartA’ and ‘PartB’ and computing a diff against the ‘ALL’ data. To confirm the root cause, we temporarily ‘froze’ our pipelines so that new updates couldn’t cause drift between the partitions, and finally confirmed that the data was 100% the same across old and new code paths.
The lesson here was—when you’ve exhausted all possible locations for bugs, take a step back and reconsider any assumptions you’ve made.
Error-handling & retries: our PersonDB micro-service is stateless and sits behind a Load Balancer. With enough request load, Load Balancers will sometimes throw errors (HTTP 5XX status codes), like 502 Bad Gateway, or 504 Gateway Timeout. Our open-source Thrift client should’ve surfaced these errors and their status codes, but it did not. Instead, the client was attempting to deserialize the response from the Load Balancer as valid Thrift data coming from PersonDB Service. We didn’t know this immediately, and all we saw was a mysterious TProtocolException. Try Googling it to see the lack of good clues online.
We used two clues to triangulate our issue:
- Our metrics pointed to a correlation between TProtocolException andLoad Balancer 5XXs.
- The stacktrace pointed to an issue in the ‘readMessageBegin’ function in the Thrift client.
We didn’t have a choice but to dive into the Thrift client and fix it. Using the stacktrace, we pieced together the most likely source of the issue, surfaced exceptions and status codes from the underlying transport layer, and configured some simple client-side retries to account for occasional 5XX errors. Our clients have now had a 100% success rate for two months and counting.
Wrapping Up with a Few Lessons
This was a fruitful project in so many ways. It was crucial to scaling our business and gave us valuable experience along the way. A few lessons come to mind:
- The ‘happy path’ of your code isn’t what you may spend the most time on. Testing, error handling, scalability, and data validations take lots of thought and energy.
- Data integrity issues warrant deep investigations. Resist the urge to think that 99.99% correctness or accuracy is “probably okay”. This isn’t the first project where we’ve uncovered bugs or issues with our data-handling code.
- Sometimes you just need to cut corners and move fast. The entire project would look different if we had a big company’s time and resources. We still have an unsolved memory leak that we’ve worked around, and it was worth it for achieving our goals.
We’re far from done with our scaling efforts, so if our work sounds exciting to you, join us and help us scale to another 10x.

Get AI Protection for Your Human Interactions




Related Posts





