Joining Abnormal Security as a New Grad Software Engineer
This January, I joined Abnormal Security as a new grad Software Engineer. As you might expect in the midst of the COVID-19 pandemic, the onboarding process was entirely remote.
Prior to graduating from MIT with my BS in Electrical Engineering and Computer Science, I had interned as a software engineer at Microsoft and Cisco Meraki, among other companies, including several startups. I knew I was interested in the intersection of cybersecurity and machine learning and I wanted to find a full-time role that would allow me to continue building my skills while working on problems in these areas.
Interviewing with Abnormal
The interview process with Abnormal really impressed me. The questions my interviewers asked all seemed tailored to the work I’d be doing as an engineer on the team and everyone was extremely open to chatting about their experiences. It sounded like a great opportunity to learn software engineering best practices from industry experts while still maintaining the fast pace of working at a startup.
When I met with Kevin Wang, VP of Engineering, for the first time, we had a long discussion about building a career in tech. Our conversation drifted from his own experience in the software industry to finding and nurturing relationships with mentors. I couldn’t help grinning after hearing about how much the company wanted to support my growth and the opportunities I’d have to take ownership as an early career engineer. Even beyond the challenges of building models to detect email attacks, I could really see myself learning and growing here.
Logging On
Flash forward a couple of months and I finally joined the Detection team at Abnormal! As my first full-time role out of school, I was pretty nervous to start, but the team made the transition so seamless. As soon as I logged onto Slack, everyone was sending over messages and scheduling coffee chats to welcome me to the team. I was blown away by the cheers from the weekly town hall meeting when all the new hires were introduced. Even without seeing the team in person, I could recognize the same passion I’d experienced during my virtual onsite.
Getting Set Up
Before I could start making pull requests, I had to learn about Abnormal’s products and systems. One of the first documents I was introduced to was our Engineering Onboarding Guide, which walked me through all of the dependencies and tools I’d need to set up before I could start working on detection. Getting your development environment created is often a stressful process, but I felt really supported. Whenever an issue came up, I could easily ping someone on Slack for help. In no time, I was ready to start contributing.
Setting Goals
During my first week, I had meetings with my manager and mentor. We went over my goals as an engineer, such as improving my software engineering and machine learning skills, and the personal milestones I wanted to achieve. They gave me some good advice about managing responsibilities and we chatted about ways to improve productivity and context-switching while doing remote work. My mentor assured me that there would be a period of ramp-up and that I should focus on building my skills before worrying about my productivity. I was surprised the next week when my manager sent me this book in the mail—Abnormal really takes personal development seriously!
Staying Connected
I’d heard about how working remotely makes it harder to get to know people. I wasn’t sure if I would be able to experience the company culture or develop relationships as well as I might in person. While it’s certainly true that a pixelated face is no stand-in for in-person interactions, I’ve found a lot to love! In my first month, I attended a fun cooking class with a chef from Mexico, happy hours in a virtual north pole, and talent shows where we learned to sing Bollywood songs and perfect a sun salute. From my one-on-ones, I got to learn about the creative passions and interests of fellow Abnormalities while also gaining a better understanding of our machine learning systems.
Starter Project
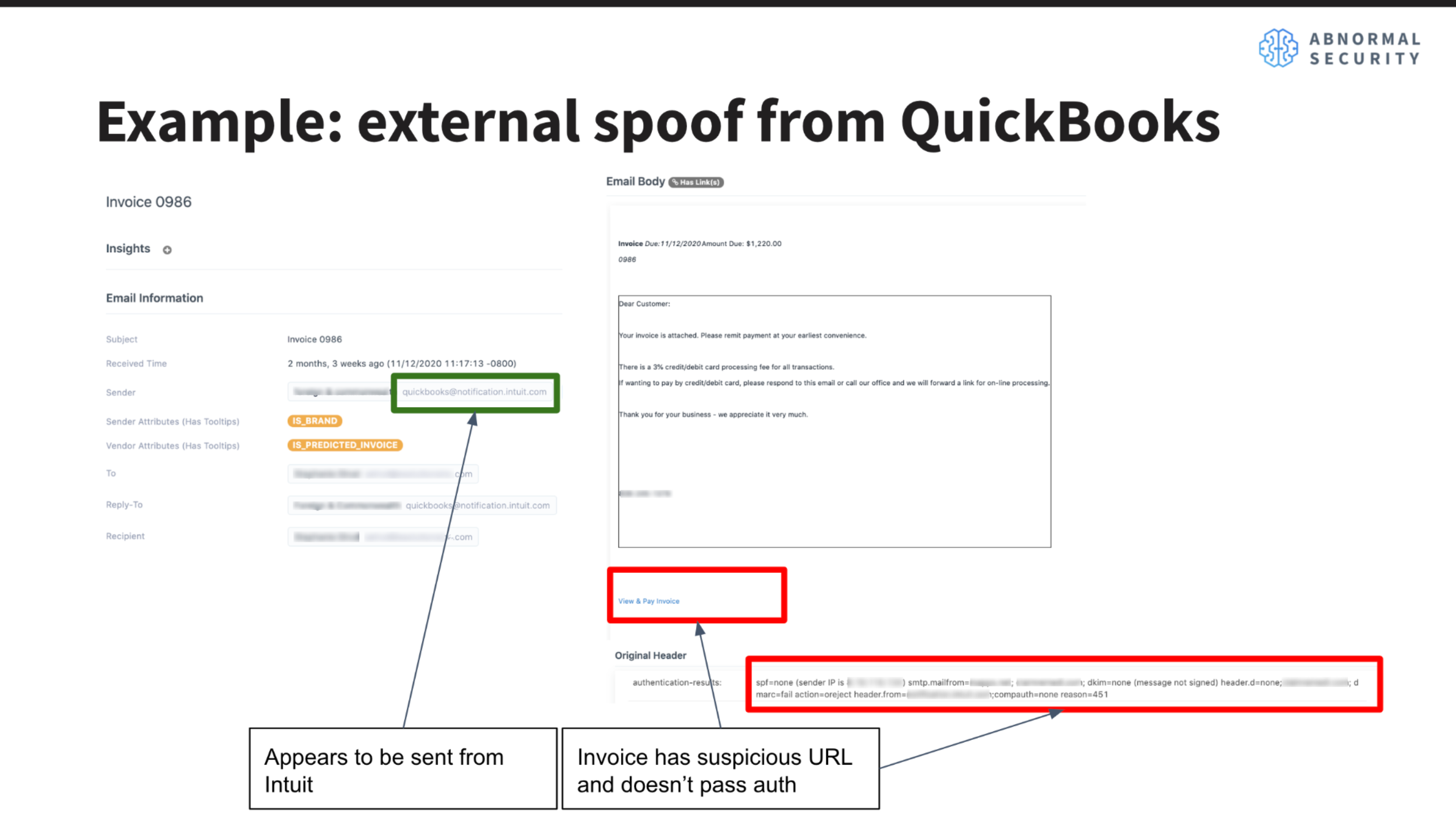
Getting to jump straight into training models within our detection system was the perfect way for me to get my feet wet, while also building up my understanding of the Abnormal codebase. The first project I had was to build a new machine learning model to classify various types of email attacks. Specifically, the goal was to identify emails that use email header spoofing in order to impersonate a sender. This usually involves manipulating the sender name and authentication headers to make the email appear to be sent by a legitimate sender. This new model would be added to Abnormal’s suite of detection models, which are eventually used to provide signals as to whether an email is likely to be a malicious attack or not.
At first, I was surprised that I would be working directly with our detection system right away. But as my mentor Lawrence mentioned, this was a great opportunity for me to make a big impact on our customers by improving the precision of our spoof detection models. Spoofed messages are a real problem for customers since it’s easier for employees within a company to click on emails being sent from a manager’s address than from a random spam address. In order to prevent phishing attacks, invoice fraud, and other major attacks from affecting employees, we want to make sure we’re able to detect these kinds of emails right off the bat.
After meeting with the other machine learning and software engineers, I was able to map out a plan of work:
- Identify the problem. We want to make sure we fully define the type of messages we’re trying to identify. In this case, we want to look through messages that we would classify as spoofs in order to group the characteristics of these messages that we should be signaling for in our detector.
- Figure out what data sources to use. We have a couple of data sources with message data from past attacks that we can use for training our model. In order to ensure that we balance performance with precision, we want to filter out the messages we don’t need while also including relevant attributes we’ll want to use in our model.
- Decide which features and model type to use. Part of the process of training models is figuring out the type of model we want to use (random forest, decision tree, logistic regression, etc.), the hyperparameters, and the features we want to include.
- Evaluate the results. This is probably the most important step. It’s important to make sure the data you’re evaluating the model on isn’t contaminated by including messages used in the training set. In addition, we want to avoid biases as much as possible so that our models will be accurate in the real world.
A lot of the process for creating datasets was already abstracted, but I still needed to run Spark jobs to extract these millions of messages we wanted to use for our training and test data. In addition, I had to manipulate Pandas DataFrames and Numpy arrays in order to test out different ways of splitting and grouping data. I also used a couple of different evaluation methods, including metrics from scikit-learn, to test the precision and recall of the model.
Something I quickly learned was that setting up an experimental framework, complete with hypothesis testing and evaluation plans, can be really helpful for reducing the amount of time spent on making small tweaks to a model. Eventually, I was able to test out different combinations of features on model types, perform hyperparameter tuning, and run a final evaluation on the spoof model. It ended up catching more than half of the false negative spoofed messages we’d previously missed, which is great for a new detector! Getting to run the detector on real data and seeing how it increased the precision of our overall model for ranking the likelihood of attacks of messages was surreal, and it was so motivating to be able to see the work I’d done in just one month make an impact.
Takeaways from My First Few Months
Starting at a new company straight out of college can be terrifying and stressful, let alone onboarding during a global pandemic. I came into the Detection team unsure of whether I’d be able to easily make the transition and start contributing to the team in a meaningful way. Fortunately, Abnormal has made me feel right at home from the first day onwards.
As my team lead Jesh says, there isn’t such a thing as a dumb question. Anytime I’m stuck or have concerns about something I’m working on, I can be sure that someone on my team is willing to step in and help me out. Having a remote knowledge base of documentation and a team culture that’s focused on collaboration also helps so much with filling in gaps of knowledge during this transition. I also love how I was able to simultaneously contribute to the codebase while also building out my understanding of our detection system.
At this point, I’m still learning the ropes but I feel much more confident about taking ownership and contributing to Abnormal’s detection products. I’m excited to build even better security products that will help our customers catch malicious attacks and to learn from the experiences of other Abnormalities. Even beyond learning to implement data transformations and evaluate PR-AUC curves, I’ve gained a lot of intuition into designing models and analyzing malicious attacks. I’d like to thank the Detection team and Dmitry, Jesh, and Lawrence for all of their guidance and feedback, and for making my onboarding experience so seamless.
Abnormal Security is currently hiring, so check out our Careers page if you’re interested in working with us.

Get AI Protection for Your Human Interactions




Related Posts





