How You Should Design ML Engineering Projects
This article originally appeared in Towards Data Science. You can read the full article below.
Machine learning engineering is hard, especially when developing products at high velocity, as is the case for us at Abnormal Security. Typical software engineering lifecycles often fail when developing ML systems.
Have you, or someone on your team, fallen into the endless ML experimentation twiddling paralysis? Found ML projects taking two or three times as long as expected? Pivoted from an elegant ML solution to something simple and limited to ship on time? If you answered yes to any of these questions, this article may be right for you.
The purpose of this article is to:
- Analyze why software engineering lifecycles fail for ML projects.
- Propose a solution with an accompanying design document template to help you and your team more effectively run ML projects.
Software and Data Science Project Lifecycles
Typical software engineering projects are about developing code and systems. They might go something like this:
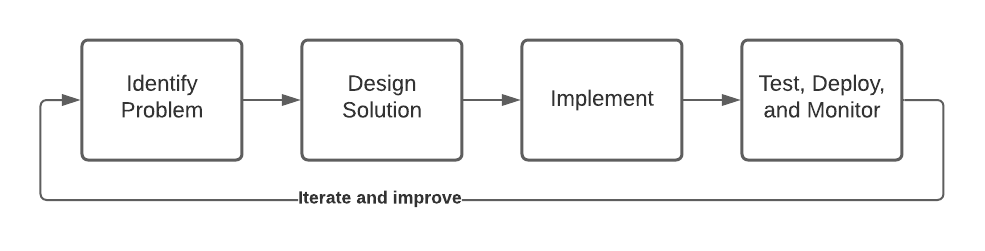
This lifecycle is clearly not what happens for ML engineering projects. What about data experimentation? What about model training and evaluation?
Maybe we should look toward data science research projects and see if their lifecycle is more suited.

This lifecycle doesn’t seem right either. Pure data science research projects are about answering questions and not about building systems. What’s the middle ground?
Understanding Machine Learning Engineering
Machine learning engineering is at a unique crossroads between data science and software engineering. ML engineers will have trouble operating in a software engineering organization if you try to force everyone to operate in the typical software development lifecycle. On the other hand, operating a machine learning team like a pure data science or research team will result in nothing getting shipped to production.
ML engineers can get frustrated when they commit to a project that requires experimentation. When they inevitably have false starts because data does not support their initial hypothesis or because wrangling the data is much more difficult than anticipated, they start falling behind committed timelines. This sense of falling behind results in a feeling that a crucial part of their job—experimentation—feels like a constant failure compared to their colleagues working on software engineering tasks.
A typical ML Engineering lifecycle goes as follows: (1) identify a problem (2) design software and experiment, which are interconnected because the models you may plan to implement will depend on which experiments work out, but you may need to design feature and model code to run your experiments in the first place (3) implement code and wrangle data, which may be interconnected because you may need to implement software to get the data you need and you may need the data to write and test the feature extraction or model training code(4) analyze data, train models, evaluate results (5) publish results (6) test, deploy, and monitor code and models.
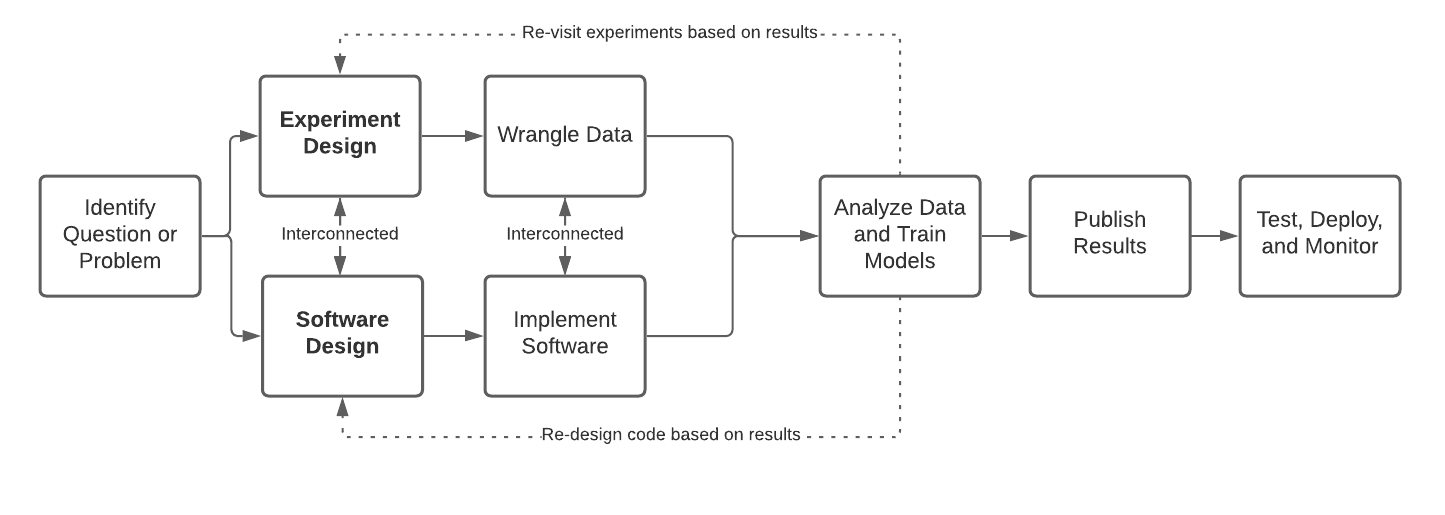
This ML engineering lifecycle is often invented on the job and not taught. It is possible to do very well by carefully laying out software and experimental design. Still, it is also easy to do poorly, leading to many false starts and winding paths toward a solution that may never be reached.
Junior ML Engineers vs Senior ML Engineers
In a fantastic article by Julie Zhuo, she illustratively compares Junior Designers vs. Senior Designers, and this visualization aptly pertains to Junior and Senior ML Engineers as well

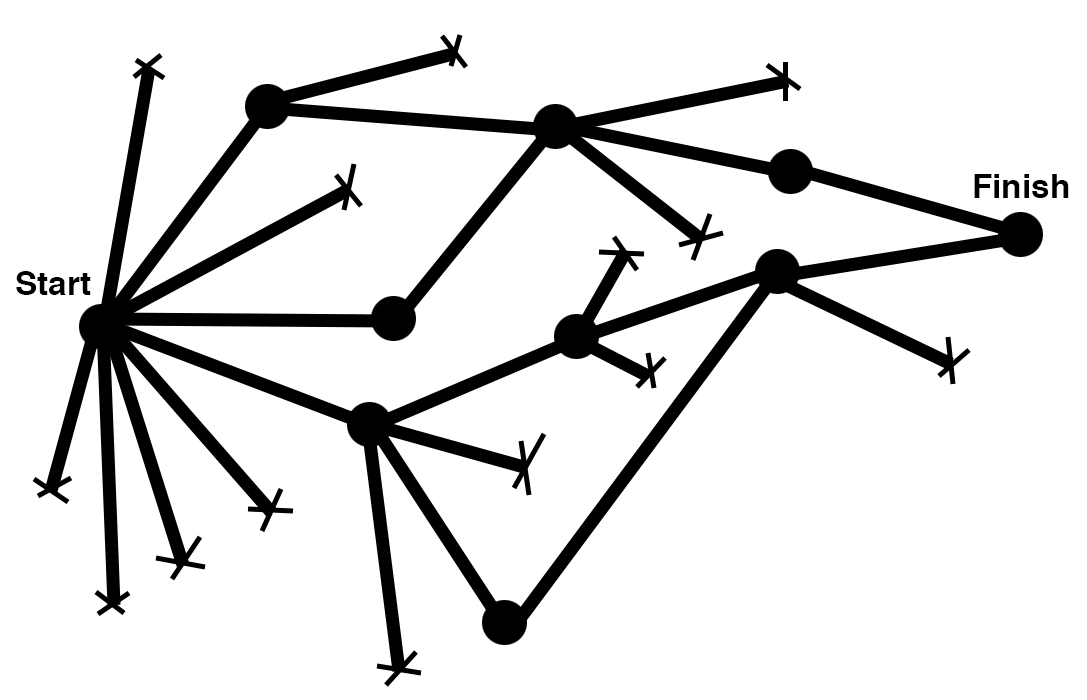
Methodical thinking and discipline are a must when iterating on experiments. Can we help ML engineers plan out work to follow this paradigm?
Design Documents to Aid ML Engineering Lifecycles
How can we encourage better ML engineering design?
A process we’ve implemented at Abnormal is to require all ML Engineering projects to go through a formal design review process using a design document template that helps the engineer do good software and experiment design simultaneously.
What should be encouraged when designing ML Engineering projects?
- Put the work into explicit forward-thinking experiments before rushing into implementation. This heads off the endless and fruitless ML/data experimentation/twiddling experiment iterations we all find ourselves in from time to time.
- Call out the *work* of experimentation as useful, whether or not the experiment validates the hypothesis. There is value to disproving a hypothesis even if it does not lead to ML product improvements.
- Design software with experiments in mind and design experiments with software in mind, i.e., what is capable of shipping to production. Wrangle your data in light of the systems you will be building and how that data will be available in production.
With these in mind, we created the template below to fill out at the beginning of any ML engineering project. An engineer should copy this template, fill in the details for their project, then present the software and experimental design to the team for feedback and iteration. This process has greatly improved the success and velocity of projects, and we highly encourage adopting this design template (or something similar) for your ML Engineering team.
Abnormal Security’s ML Design Document Template
We use this template at the start of every project. Feel free to use directly, modify, and share!
Problem Statement
What are we specifically trying to solve, and why are we solving it now? A strong justification will tie this back to a product or customer problem.
Goals
Software Goals
Describe the software system we wish to build and its capabilities.
Metric Goals
What is the desired metric improvement, how are we going to measure the impact of this work, and why do we want to improve the system in this way?
- Bad Example: Improve model’s performance
- OK Example: Improve AUC by X% for the model
- Good Example: Improve recall by X% for the class of false negatives without decreasing recall for any other classes by more than Y%.
Include expected metrics tradeoffs, if any. For example, Increase recall without decreasing precision by more than 5%.
Experiment Design
Unlike pure software projects, data science / ML projects often require data exploration, experimentation, failure, and changing design along the way when data has been collected. To help make a project successful, it is helpful to lay out your potential branching points and how you will make decisions along the way. Additionally, all experiments should be evaluated against a baseline, which is either a simple solution to the problem (simple algorithm, simple heuristic) or the current production solution if one exists.
Data Motivation
Describe the problem that should be solved and use data to validate that this is indeed a worthy problem to solve. Is this actually going to have a real impact?
Hypotheses
Hypothesis 1: Method A will improve metric B by X% over baseline.
- Method: Describe the methodology you are approaching. For example, this might be a model architecture we are testing, a new feature we are adding, etc.
- Metric: Describe the metric or metrics we will use to evaluate the method.
- Success Criteria: The measured metric results that will indicate success in this hypothesis. Ideally should be measured against a baseline.
Timebox: X days, then check in with the team to decide the next steps. - Failure Next Steps: For example, go on to try Hypothesis 2.
- Success Next Steps: For example, push this model to production.
Hypothesis 2: …
The same set of questions for each hypothesis
...
Software Design
Describe the software systems and data pipelines needed to execute this project. What software needs to be built? What services and databases? What data will need to be available in production to run your model? Feel free to use normal software design documentation principles here.
Execution
What will be delivered and when will it be delivered. A strong plan will provide incremental value and will allow us to get to the crawl state quickly.
- Crawl: Minimum design to prove the efficacy of change before we invest too much time in software development.
- Walk: More thorough design aimed to be a relatively complete component.
- Run: Long-term design here; how would we make this a really first-class system or model.
Considerations
- Success criteria to launch? Describe metrics evaluated to advocate launching this model or change into production.
- What could go wrong? Describe all possibilities that might go wrong when we launch this.
- Which product surfaces could be affected?
- How will this impact customers?
- How will we monitor?
- What will we do to roll back?
- What are the security and privacy considerations? Include everything that must be taken into consideration.
- What impact on security could this change have?
- What impact on privacy could this change have?
Appendix: Experiment Log
Keep track of the results of each hypothesis tested and the decisions made along the way, branching points, learnings, revised hypotheses, and so on. It’s beneficial to remind yourself later and share how you approach this type of problem with others on the team.
And that's it! We hope this helps you design better machine learning projects for your tough problems.
Interested in learning more about how we work on Machine Learning at Abnormal? Check it out here, or join us!

See the Abnormal Solution to the Email Security Problem
Protect your organization from the full spectrum of email attacks with Abnormal.